




前言
SRE是一个体系化的工程,SRE体系的建设涉及的内容繁多,比如日常需求处理、容量规划、资源部署、监控告警、预案梳理、灾备演练、OnCall值班、应急事件响应、故障处理、运维自动化建设等。故障是众多事项的一个交汇点。
- SRE团队的响应速度
- 对服务的掌控能力
- 监控告警的覆盖是否完整
- 配置是否合理
- 灾备预案的体系是否完善
- 是否充分的做了灾备演练
- 应急预案是否有效
SRE的工作职责

- 稳定性是核心职责,这是SRE区别于SA、OP、PE的点。
- 通过建设工具、平台、基础设施的建设来提高效率
- 成本连同效率就是降本增效。
稳定性建设

- 什么是稳定性
- 如何度量稳定性
- 如何设置稳定性目标
- 如何提升稳定性
度量稳定性
在业界我们通常用MTBF和MTTR这两个关键指标来衡量稳定性,这两个指标分别是「平均故障时间间隔」(Mean Time Between Failure)、「平均故障修复时间」(Mean Time To Repair)。

- 几个关键的时间点:
故障维修结束:上一次故障恢复结束的时间;
故障开始:故障开始发生的时间;
故障维修开始:开始介入故障,开始处理的时间。 - 根据上面这几个时间点就把时间划分为了几个时间段:
维修结束 -> 故障开始:T1
故障开始 -> 维修开始:T2
维修开始 -> 维修结束:T3 - 其中
T1的平均值为「平均无故障时间」,MTTF(Mean Time To Failure)
T2+T3的平均值为「平均修复时间」,MTTR(Mean Time To Repair)
T1+T2+T3的平均值为「平均故障间隔」,MTBF(Mean Time Between Failure)
设定稳定性目标
提高MTBF,降低MTTR


提升稳定性
MTTR的指标被细化之后,我们的目标也就变成了降低这些细化之后的指标;我们可以分而治之、各个击破。

- MTTI阶段
多管齐下;尽可能用更多的手段来覆盖可以发现、暴露问题的通道,包括完善监控的覆盖,建设体系化的监控系统。 - MTTK阶段
工具赋能;这个过程中需要更多的借助工具、平台的能力,建设健全运维系统,比如监控平台、日志平台、链路跟踪平台等,如果能力允许也可以去尝试建设“根因自动定位”系统。 - MTTF阶段
完备预案、一键应急、紧密协作;这个是在故障处理过程中最核心的部分,是真正可以让服务恢复正常的阶段;这个过程有比较多的前置依赖,也就是需要我们在平时做好储备的,比如建立健全预案体系,将预案的执行手段尽可能沉淀到工具平台中,尽可能做到一键直达,缩短预案执行的路径。其次这个过程中可能还会涉及到部门内部、部门之间的协作,尤其是在处理重大故障的场景;这时候就需要有一套可以让大家紧密协作的流程或共识,让大家可以信息互通、各司其职、有条不紊。 - MTTV阶段
自动校验;这个过程也是需要尽可能依赖自动化的手段去做。

- Pre-MTBF
预案建设、灾备演练、OnCall值守等; - MTTR
应急响应; - Post-MTBF
故障复盘、故障改进、OnCall值守等。
故障管理
故障管理分为故障前、故障中和故障后,在每个环节都有一些核心的工作内容和目标。

- 故障前
故障预防、灾备预案;目标是尽可能地做足准备工作,毕竟有背方可无患; - 故障中
发现、定位、解决故障;目标是尽可能的提高效率,缩短故障恢复的时间; - 故障后
故障复盘、故障改进;目标是尽可能多的从故障中吸取教训,反思和学习,完善和修复故障中暴露出来的问题。
故障前
关键内容:监控覆盖、架构设计、容量评估、灾备预案、灾备演练、还有持续交付。

监控覆盖的话比较容易理解,服务上线后,只有拥有足够的监控手段,并且尽可能多的覆盖服务的各个环节,才有可能在后面发生问题的时候,快速的感知到。

- 常规的有一些第三方的拨测、第三方的APM。除了一些商用的产品,当然也有一些免费的工具是可以用的。
- 应对一些流媒体的应用,我们自研了一套融合CDN的监控还有流媒体的监控。这个其实也比较关键,因为现在业务体量大了之后,CDN是不可避免的会用到,但如果没有这部分监控的话,CDN质量就要依赖于用户反馈,链路就会比较长。




架构设计
架构设计可能会更偏业务侧一些。我们在故障之前,要尽可能做好服务的架构设计,同时在做一些预案之前,也要把服务架构做好梳理。只有当我们把服务的架构了然于胸,才更有可能在故障发生的时候从容不迫,更好地定位问题。
要更多去加入柔性设计,也就是说你的服务要具备一些像降级熔断、故障隔离这些手段,要有这样的柔性设计在里边。这样架构可以提供这些能力,后面才能更好地去做服务的保障。
再有一点就是,要尽可能的去规避常规的风险点,比如说单点之类的;同时还要尽可能地去规避架构里面常见的坑。

容量评估
容量评估其实就是我们的服务在上线之前,要去对服务的承载能力做一个压测,这样我们才能更好的了解服务上线之后的状态。然后我们基于这个,再根据业务方量级的评估,去规划服务的容量。
容量评估其实是不能完全依赖于压测的。在压缩之前,要基于我们对自己服务的理解,包括每一条请求大概会耗费多少资源等,要有一个基础的认识,再基于这些认识去评估大概需要用多少后端资源、大概会用多少CPU内存,这些东西是可以用数学计算的方法来计算出来的。

灾备预案和灾备演练
这两点是比较关键的,跟故障会更强相关。

- 服务梳理
在服务梳理阶段,要基于前面的架构图等来梳理请求链路,要分段分层地梳理请求都经历了哪些层次、有哪些阶段、经过了哪些设备、周边有哪些依赖(包括内部的服务依赖、后端的资源依赖、第三方的依赖等),然后还要梳理架构目前是不是有什么风险、流量有没有经过一个单点、有没有哪个点可能是存在瓶颈的……这些都是我们在服务梳理阶段需要去梳理清楚的。 - 预案梳理
了解各种情况后,就可以梳理相应的预案了。仔细分析应该用什么样的手段来覆盖,将风险各个击破;然后要尽可能地做多级预案,因为预案如果只有一级的话,容灾能力是不够柔性的;此外,还要借助到一些智能调度的手段;最后就是柔性设计,前面也有提到,是更偏业务侧一些,也就是说在服务里要有尽可能多的手段来做自己的一些failover,可以去做一些降级、熔断等。 - 沙盘推演
梳理出来预案后,并不是直接到做演练。要了解预案是不是真的有效,不是直接做演练,而应该是先想清楚。我的建议是去做沙盘推演。在这个过程里,我们要尽可能去发动多的部门协作起来,来看我们的预案是不是有效。毕竟人多力量大,并且不同团队的人对业务可能有不同的理解,在这种头脑风暴下,就有可能碰撞出更多的可能性。然后在这个过程里,会基于一些可能的故障场景、case等来做推演,当故障场景A出现了,梳理出了预案A’,那 A’能不能把故障A完全解决掉?在解决故障场景的时候,有没有引入一些其他的风险点或问题?在这个过程里面,我们都要想清楚,当得出一个大家都认可的推演结果后,预案才推演完了。 - 预案落地
这一步是需要做落地,包括文档输出、功能实现、架构适配、工具建设。 - 预案演练
落地之后,要通过演练的方法来验证预案是不是真的有效。无损演练和轻损演练:我们做故障演练要尽可能地做到对业务无损,但有些预案本身应对的故障场景就是会损害业务的,那这种时候我们要尽可能降低这种演练带来的损失,比如说选不同的时间段、流量的控制、灰度之类的,尽量去做轻损的演练,既然我们是通过故障演练的方式来确保预案有效,那肯定不能因为故障演练而演练出一个大的故障,这就有些得不偿失了;还有就是单点演练跟组合演练:你的演练到底是要一次演练某个模块,还是说要把一个大故障场景里所有涉及的点都演练一遍?这个也是我们在预案演练里需要考虑的。
持续交付

故障中
故障真的发生了?去发现定位和恢复。核心手段::监控告警、日志分析、链路跟踪、故障隔离、容灾切换、降级熔断。


由于红色这块故障引发了另外一个异常,接连引发了一个又一个的异常。通过这张告警图,收获了更多的信息:首先知道系统挂了,或者系统异常了,然后这次异常大概是由什么引起的。一张图就可以让你非常快速地感知。



日志分析、链路跟踪、预案执行都是定位手段,在已经定位问题之后,并且匹配了相应的预案,要求去执行预案。当然前提是有相应的预案应对故障场景。然后依据操作手册,分别按不同的故障层次去执行处理。

恢复之后还要确认执行结果,看服务是否恢复正常。
故障后
在故障后,我们应该做好以下环节:故障复盘、故障改进、预案完善、容量压测、故障模拟、周边清查。

- 预案完善
故障发生之前有做过预案,这些预案是不是完善的?在故障处理的过程中,有没有暴露出问题?是否要完善之前的预案中做的不完善的地方等等; - 故障模拟
意思是用某种手段模拟某些故障,提前知道该如何解决这些问题; - 周边清查
应该具备举一反三的能力,比如A服务出故障,那么A服务周边有一些相关联的服务有可能会受到影响。
举个例子,比如集群里面有N台机器,收到机器A磁盘接近100%的一条告警,只需处理机器A就可以了吗?当然不是,在处理完该异常之后,肯定要查看同集群的其他机器是否存在类似情况。

在故障复盘的过程中,要把这些操作的时间点一一还原回去,才能完整地回看操作是否合理有效。

到此做个总结,故障本质上是持续迭代的,当故障发生了,开始恢复、复盘、改进、验收,回到稳定运行的状态,再过一段时间又出现故障。同时,服务也持续地迭代,因此要不断去提升稳定性,这是我们都逃不出的一环。

故障管理体系
做好故障管理,需要建设一些SRE体系提供支撑。

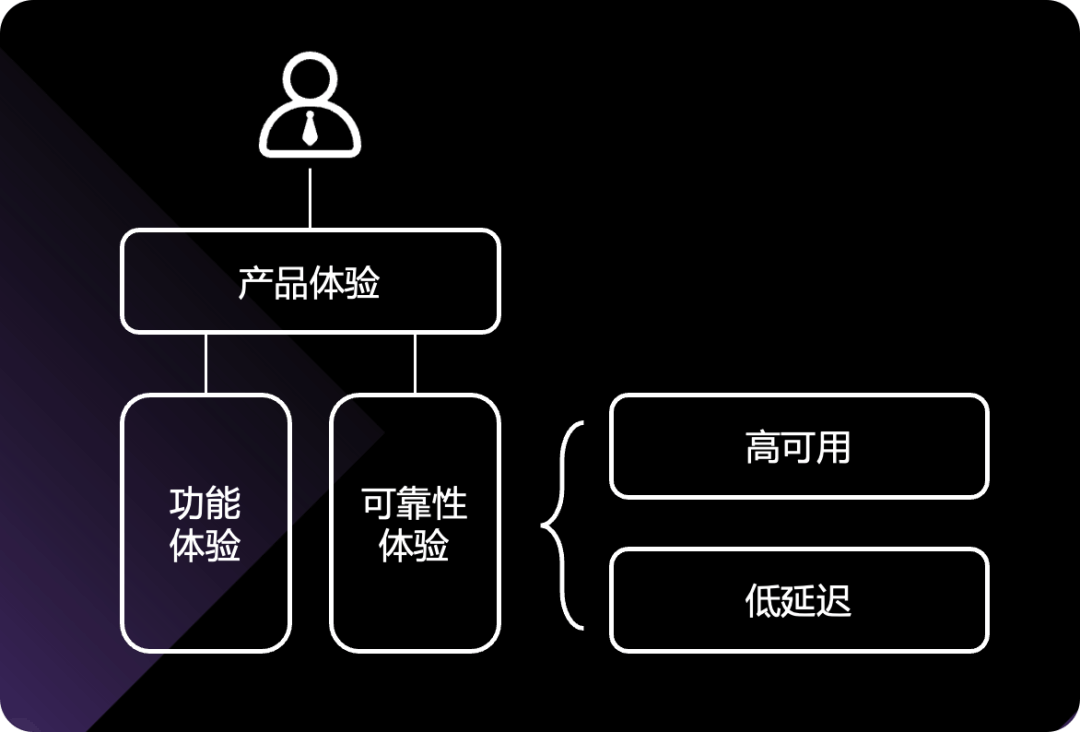
可用性体系
SLI是指标,SLO是目标,SLA是我们的目标加上目标未达成的后果

- 容量(Volume)
服务承诺的最大容量是多少,从QPS、TPS、流量、连接数、吞吐思考; - 可用性(Availability)
服务是否正常,看HTTP状态码2xx的占比; - 延迟(Latency)
服务响应速度是否够快,rt是否在预期范围内; - 错误率(Errors)
错误率有多少,看HTTP状态码5xx的占比; - 人工介入(Tickets)
是否需要人工介入处理,考虑人工修复。
故障定级、定性、定责
定级通用标准

定级个性化标准
除了通用标准,还有一些没有被囊括到体系中来,比如某些电商类、商业化、广告类和金融类的业务,有可能造成资产损失,那么不同的部门会有不同的故障管理的定级策略。

定性有效分类

定责:判定原则
定责任并不意味着处罚。我们整体的故障管理从原则上来说尽量不指责,但不指责不代表着可以持续犯错误。

上下游原则:根据服务的上下游依赖程度去做判断;
健壮性原则:根据服务的健壮性定性。例如服务A挂掉导致服务B出问题,这时候责任不能完全划分到服务A上,还要考虑到服务B本身的健壮性;
第三方默认无责:内部做故障定位时,默认第三方无责,当然该追责的还是会追责。
错误预算
SRE里经常听到错误预算,如何做到实际落地?前面讲了故障的定级规则,明确定级规则之后,不同的故障被定为ABC级,按对应计分标准扣分。扣的分数来源于给出的预算。我们每半年为一个OKR考核周期,在一个考核周期里面每个BU会分到一定的故障分,允许在考核周期里由于故障被扣分,如果分数扣完了意味着错误预算用完了。

组织结构支撑

当故障发生了,基于判定规则给故障定级、定责。定级意味着每个级别产生对应的故障分;定责会涉及到故障的拆分,比如发生了一个故障,它由A、B两个部门共同承担。根据定责发现责任上A、B部门实际是五五开,因此A、B平分故障分,再从A、B部门的BU负责人各自的错误预算里扣除故障分。
通过这种方式就能约束好BU吗?当然不是,要用行政手段来保障,那就是OKR。周期OKR里需要有服务稳定性的目标项才行,把服务稳定性写进OKR后,BU出于压力而去共同做好故障管理。在上述这种组织支撑的情况下,才能更好地推行故障管理。
SRE体系建设

稳定性建设
按照 MTBF和MTTR,把日常时间分成几段,不同时段里要做哪些事情?先是建设演练、Oncall值班,然后应急响应,最后复盘改进、再Oncall。在一个循环里面完成了SRE的工作。
PPTV
即PPT+V。PPT包涵了人员、流程、技术,是ITIL中的IT管理的三要素。SRE体系建设同样无法脱离这个模型,做好故障管理要有一个合适的组织结构、流程流程保障。
未来展望
AIOps和混沌工程Chaos Engineering

评论 (0)