



搜索到
25
篇与
的结果
-
 从零搭建一个手机号过滤平台:PBlack 架构全解析 今天聊聊 PBlack——一个开源的手机号黑名单/白名单检测平台。我会从架构设计的角度,拆解它是如何解决这些痛点的,以及为什么选择 Vue + Django + Go 这样的技术组合。为什么需要手机号过滤?先说说背景。在金融风控、电商防刷、社交平台注册这些场景里,手机号是最基础的身份标识。但问题来了:骚扰电话营销:用户被各种推广电话轰炸,体验极差羊毛党批量注册:用虚拟号、接码平台批量薅羊毛欺诈风险:黑名单号码反复作案,平台损失巨大传统的解决方案要么简单粗暴(直接拒接所有陌生号),要么成本太高(每次都要调用第三方接口)。PBlack 的设计目标就是:既要快,又要准,还要省钱。整体架构:三层分离PBlack 采用前后端分离的微服务架构,核心分为三层:┌─────────────────────────────────────────────────────────┐ │ 前端层 (pfront) │ │ Vue 3 + TypeScript + Vite │ │ 管理界面、API 密钥管理、消费统计看板 │ └─────────────────────────────────────────────────────────┘ │ ▼ ┌─────────────────────────────────────────────────────────┐ │ API 服务层 (papi) │ │ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ │ │ phone-filter │ │ teddy-api │ │ pfront-api │ │ │ │ -api (Go) │ │ -proxy (Go) │ │ (Go) │ │ │ │ 黑名单检测 │ │ 上游代理 │ │ 认证/消息 │ │ │ └──────────────┘ └──────────────┘ └──────────────┘ │ └─────────────────────────────────────────────────────────┘ │ ▼ ┌─────────────────────────────────────────────────────────┐ │ 数据与管理后台层 │ │ Django + PostgreSQL + Redis │ │ 用户管理、号码库、访问记录、缓存加速 │ └─────────────────────────────────────────────────────────┘这个分层不是拍脑袋决定的。每一层都有自己的职责,而且可以独立部署、独立扩展。技术选型:为什么这样组合?前端:Vue 3 + Vite选择 Vue 3 而不是 React,主要是考虑开发效率和团队熟悉度。Vite 的冷启动速度比 Webpack 快一个数量级,本地开发体验很好。TypeScript 是必须的——手机号过滤涉及大量的 API 接口对接,类型安全能避免很多低级错误。管理后台:DjangoDjango 的 admin 界面是开箱即用的。用户管理、API 密钥管理、黑白名单维护这些功能,用 Django 的 ModelAdmin 几行代码就能搞定。如果用 Go 写后台,光 CRUD 接口就要写一堆。Django 的 ORM 和 admin 在这种场景下是降维打击。核心检测服务:Go这是整个系统的性能瓶颈所在。手机号检测是高频操作,QPS 可能达到几千甚至上万。Go 的 goroutine + channel 模型非常适合这种高并发、低延迟的场景。实测下来,单机可以轻松支撑 10k+ QPS。// 核心检测逻辑:Redis Set 的 O(1) 查询 func (s *BlacklistService) CheckSingleNumber(phone string) (bool, error) { isBlacklisted, err := database.IsPhoneInBlacklistSet(phone) if err != nil { return false, err } s.updateStats(isBlacklisted) return isBlacklisted, nil }数据流转:一次检测请求的全流程来看看一个黑名单检测请求是怎么处理的:客户端 → phone-filter-api → 签名验证 → 用户鉴权 → Redis 查询 ↓ 客户端 ← 返回结果 ← 组装响应 ← 命中判定 ← 黑名单 Set关键设计点:Redis Set 存储:黑名单和白名单分别用 Redis 的 Set 数据结构存储,SISMEMBER 命令是 O(1) 复杂度,百万级号码也能毫秒级响应多级检测策略:level=1:只查黑名单,命中即拦截level=2:只查白名单,用于"只允许特定号码"的场景level=3:黑名单优先,未命中时调用上游 API 二次确认批处理优化:访问记录和消费记录不实时写入数据库,而是先放入内存队列,每 5 秒批量 flush 一次,大幅降低数据库压力// 后台批处理器,降低主链路延迟 type BatchProcessor struct { accessRecords []*models.AccessRecord consumptionRecords []*models.ConsumptionRecord mutex sync.Mutex batchSize int // 默认 100 条批量写入 } func (bp *BatchProcessor) startBackgroundProcessing() { ticker := time.NewTicker(5 * time.Second) for range ticker.C { bp.flushRecords() // 定时批量刷盘 } }安全设计:不只是黑名单PBlack 的安全机制是多层防护:1. 签名验证每个请求必须携带 appId、timestamp、sign 三个参数。签名算法如下:sign = MD5(appId + timestamp + appSecret)timestamp 必须在 5 分钟内,防止重放攻击。2. IP 白名单每个 API 密钥可以绑定允许的 IP 列表,即使密钥泄露,攻击者也无法从其他 IP 调用。3. 余额与配额控制每个用户有独立的余额和单价设置,每次检测按单价扣费。余额不足时自动拒绝服务。部署架构:从开发到生产本地开发时,用 Docker Compose 一键启动所有依赖:# postgres/docker-compose.yaml services: postgres: image: postgres:15-alpine ports: - "5432:5432" environment: POSTGRES_DB: phonedb POSTGRES_PASSWORD: uWNZugjBqbcf8dxC生产环境建议:Nginx 反向代理:SSL 终止、静态资源缓存、限流systemd 进程守护:API 服务和 Worker 分别托管PostgreSQL 主从:读写分离,查询走从库Redis Cluster:支持横向扩展性能数据在 4C8G 的云服务器上实测:指标数值单机 QPS12,000+平均响应时间3-5msRedis 命中率99.8%批处理延迟< 5s总结PBlack 的架构设计遵循几个核心原则:职责分离:Django 做管理、Go 做性能、Vue 做交互,各取所长缓存优先:Redis Set 是核心,数据库只是持久化备份批处理降载:非关键路径异步化,主链路保持轻量安全第一:签名 + IP 白名单 + 余额控制,多层防护这套架构已经在实际业务中跑了半年多,处理了几千万次检测请求。如果你也在做类似的风控系统,希望这些经验对你有帮助。下篇预告:《30 分钟跑起来:PBlack 本地开发环境搭建实战》
从零搭建一个手机号过滤平台:PBlack 架构全解析 今天聊聊 PBlack——一个开源的手机号黑名单/白名单检测平台。我会从架构设计的角度,拆解它是如何解决这些痛点的,以及为什么选择 Vue + Django + Go 这样的技术组合。为什么需要手机号过滤?先说说背景。在金融风控、电商防刷、社交平台注册这些场景里,手机号是最基础的身份标识。但问题来了:骚扰电话营销:用户被各种推广电话轰炸,体验极差羊毛党批量注册:用虚拟号、接码平台批量薅羊毛欺诈风险:黑名单号码反复作案,平台损失巨大传统的解决方案要么简单粗暴(直接拒接所有陌生号),要么成本太高(每次都要调用第三方接口)。PBlack 的设计目标就是:既要快,又要准,还要省钱。整体架构:三层分离PBlack 采用前后端分离的微服务架构,核心分为三层:┌─────────────────────────────────────────────────────────┐ │ 前端层 (pfront) │ │ Vue 3 + TypeScript + Vite │ │ 管理界面、API 密钥管理、消费统计看板 │ └─────────────────────────────────────────────────────────┘ │ ▼ ┌─────────────────────────────────────────────────────────┐ │ API 服务层 (papi) │ │ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ │ │ phone-filter │ │ teddy-api │ │ pfront-api │ │ │ │ -api (Go) │ │ -proxy (Go) │ │ (Go) │ │ │ │ 黑名单检测 │ │ 上游代理 │ │ 认证/消息 │ │ │ └──────────────┘ └──────────────┘ └──────────────┘ │ └─────────────────────────────────────────────────────────┘ │ ▼ ┌─────────────────────────────────────────────────────────┐ │ 数据与管理后台层 │ │ Django + PostgreSQL + Redis │ │ 用户管理、号码库、访问记录、缓存加速 │ └─────────────────────────────────────────────────────────┘这个分层不是拍脑袋决定的。每一层都有自己的职责,而且可以独立部署、独立扩展。技术选型:为什么这样组合?前端:Vue 3 + Vite选择 Vue 3 而不是 React,主要是考虑开发效率和团队熟悉度。Vite 的冷启动速度比 Webpack 快一个数量级,本地开发体验很好。TypeScript 是必须的——手机号过滤涉及大量的 API 接口对接,类型安全能避免很多低级错误。管理后台:DjangoDjango 的 admin 界面是开箱即用的。用户管理、API 密钥管理、黑白名单维护这些功能,用 Django 的 ModelAdmin 几行代码就能搞定。如果用 Go 写后台,光 CRUD 接口就要写一堆。Django 的 ORM 和 admin 在这种场景下是降维打击。核心检测服务:Go这是整个系统的性能瓶颈所在。手机号检测是高频操作,QPS 可能达到几千甚至上万。Go 的 goroutine + channel 模型非常适合这种高并发、低延迟的场景。实测下来,单机可以轻松支撑 10k+ QPS。// 核心检测逻辑:Redis Set 的 O(1) 查询 func (s *BlacklistService) CheckSingleNumber(phone string) (bool, error) { isBlacklisted, err := database.IsPhoneInBlacklistSet(phone) if err != nil { return false, err } s.updateStats(isBlacklisted) return isBlacklisted, nil }数据流转:一次检测请求的全流程来看看一个黑名单检测请求是怎么处理的:客户端 → phone-filter-api → 签名验证 → 用户鉴权 → Redis 查询 ↓ 客户端 ← 返回结果 ← 组装响应 ← 命中判定 ← 黑名单 Set关键设计点:Redis Set 存储:黑名单和白名单分别用 Redis 的 Set 数据结构存储,SISMEMBER 命令是 O(1) 复杂度,百万级号码也能毫秒级响应多级检测策略:level=1:只查黑名单,命中即拦截level=2:只查白名单,用于"只允许特定号码"的场景level=3:黑名单优先,未命中时调用上游 API 二次确认批处理优化:访问记录和消费记录不实时写入数据库,而是先放入内存队列,每 5 秒批量 flush 一次,大幅降低数据库压力// 后台批处理器,降低主链路延迟 type BatchProcessor struct { accessRecords []*models.AccessRecord consumptionRecords []*models.ConsumptionRecord mutex sync.Mutex batchSize int // 默认 100 条批量写入 } func (bp *BatchProcessor) startBackgroundProcessing() { ticker := time.NewTicker(5 * time.Second) for range ticker.C { bp.flushRecords() // 定时批量刷盘 } }安全设计:不只是黑名单PBlack 的安全机制是多层防护:1. 签名验证每个请求必须携带 appId、timestamp、sign 三个参数。签名算法如下:sign = MD5(appId + timestamp + appSecret)timestamp 必须在 5 分钟内,防止重放攻击。2. IP 白名单每个 API 密钥可以绑定允许的 IP 列表,即使密钥泄露,攻击者也无法从其他 IP 调用。3. 余额与配额控制每个用户有独立的余额和单价设置,每次检测按单价扣费。余额不足时自动拒绝服务。部署架构:从开发到生产本地开发时,用 Docker Compose 一键启动所有依赖:# postgres/docker-compose.yaml services: postgres: image: postgres:15-alpine ports: - "5432:5432" environment: POSTGRES_DB: phonedb POSTGRES_PASSWORD: uWNZugjBqbcf8dxC生产环境建议:Nginx 反向代理:SSL 终止、静态资源缓存、限流systemd 进程守护:API 服务和 Worker 分别托管PostgreSQL 主从:读写分离,查询走从库Redis Cluster:支持横向扩展性能数据在 4C8G 的云服务器上实测:指标数值单机 QPS12,000+平均响应时间3-5msRedis 命中率99.8%批处理延迟< 5s总结PBlack 的架构设计遵循几个核心原则:职责分离:Django 做管理、Go 做性能、Vue 做交互,各取所长缓存优先:Redis Set 是核心,数据库只是持久化备份批处理降载:非关键路径异步化,主链路保持轻量安全第一:签名 + IP 白名单 + 余额控制,多层防护这套架构已经在实际业务中跑了半年多,处理了几千万次检测请求。如果你也在做类似的风控系统,希望这些经验对你有帮助。下篇预告:《30 分钟跑起来:PBlack 本地开发环境搭建实战》 -
从零搭建一个短信平台:LESMS 架构全解析 短信服务看似简单,但真要自己搭一个能支撑业务运转的平台,坑比想象中多得多。去年有个朋友找我吐槽:公司每个月短信费用好几万,想自建平台省点钱。我反问了他三个问题——高并发怎么扛?通道故障怎么切?账单对不上怎么办? 他沉默了。这就是短信平台的真相:发一条短信容易,发一亿条还能稳定、安全、可追踪,完全是另一回事。今天聊聊我自己写的 LESMS这个项目,看看一个轻量级企业短信平台是怎么从 0 到 1 搭建起来的。一、为什么要自己搭短信平台?先泼点冷水——大部分公司不需要自建短信平台。直接接阿里云、腾讯云,API 调一下就能用,省心省力。但以下几种情况,自建就有意义了:成本敏感:月发送量过百万,第三方平台的单价和附加费会吃掉不少利润数据合规:金融、医疗行业,用户手机号不能外流到第三方功能定制:需要特殊的签名审核流程、定时发送策略、精细化的通道调度技术储备:团队有能力维护,且业务长期依赖短信触达LESMS 的定位很明确:中小型企业的自建方案,不求大而全,但求核心链路稳、二次开发易。二、三模块架构设计整个系统拆成三大块,每块只干一件事:1. Django 管理后台:业务的"大脑"Django 在这里扮演两个角色:一是客户中心 API。用户注册、登录、余额查询、发送记录查看,这些面向客户的接口都由 Django 提供。用 Django REST Framework(DRF)写起来很快,自带序列化、权限控制、限流。二是运营管理后台。基于 Django Admin 改造的管理界面,运营人员可以在里面审核签名、配置通道、查看统计报表。SimpleUI 美化了一下,至少不像原生 Admin 那么丑。关键模块包括:用户管理:实名认证、企业认证、余额与计费消息管理:模板审核、签名报备、上下行记录通道管理:多运营商通道配置、黑名单管理充值管理:套餐、订单、卡密核销2. Vue 3 前端:用户的"门面"前端用的是 Vue 3 + TypeScript + Element Plus,基于 Vben Admin 框架二次开发。为什么不用 Django 自带的模板?因为现代前端工程化已经成熟了,Vue 的组件复用、状态管理、构建优化都比传统后端渲染强太多。前端主要承载:客户自助服务:发送短信、查看记录、管理通讯录可视化数据:发送成功率、消费趋势、通道质量开发者工具:API 密钥管理、SDK 下载、调试控制台3. Go API 服务:性能的"发动机"这是整个系统的性能担当,用 Go + Gin 框架实现。短信发送有几个特点:高并发、低延迟、重可靠。Django 是同步阻塞模型,处理这种场景比较吃力;Go 的 goroutine + channel 天然适合高并发网络 IO。Go 服务负责的核心功能:短信发送接口:接收请求、校验签名、写入队列Worker 调度:从 Redis 队列取任务,分发到不同运营商通道状态回执:接收运营商的送达报告,更新数据库上行处理:处理用户回复的短信(MO)三、技术选型背后的思考有人可能会问:为什么搞这么复杂,用一种技术栈不行吗?当然行,但会有代价。模块选型理由管理后台Django快速开发、生态成熟、Admin 开箱即用核心 APIGo高并发性能、部署简单、资源占用低前端Vue 3组件化、TypeScript 支持好、团队熟悉数据库PostgreSQLACID 保障、JSON 字段支持、运维友好队列/缓存Redis原子操作丰富、持久化可选、生态完善一句话总结:让合适的工具做合适的事。Django 适合业务逻辑复杂、变更频繁的场景;Go 适合性能敏感、高并发的场景。两者通过 REST API + Redis 队列协作,既保留了各自的优势,又避免了过度耦合。四、一条短信的完整旅程光讲架构有点抽象,我们跟踪一条短信从用户点击"发送"到手机收到的全过程:第一步:前端提交用户在 Vue 界面填写手机号、选择模板、点击发送。前端组装请求体,带上时间戳、nonce、签名,调用 /api/v1/sms/send。第二步:Go 服务接入Go 服务收到请求,依次执行:中间件链:CORS → 日志 → 签名校验 → 限流检查参数校验:手机号格式、模板是否存在、余额是否充足写入队列:将任务序列化后推入 Redis 队列第三步:Worker 调度Worker 进程从队列取出任务:解析手机号前 7 位,识别归属运营商(移动/联通/电信)查询用户的通道配置策略选择最优通道,HTTP 调用运营商网关第四步:运营商处理运营商网关返回提交结果(成功/失败),Worker 记录提交状态。真正的送达是异步的——运营商会在短信送达后推送状态报告。第五步:状态回执运营商回调 Go 服务的 /callback/status 接口,携带手机号、状态、时间戳。Go 服务更新数据库中的发送明细,同时触发计费扣减。第六步:用户感知用户在前端刷新页面,看到"已送达"状态。如果失败了,能看到失败原因(余额不足、黑名单拦截、通道故障等)。整个过程通常在 3-5 秒内完成,其中大部分时间花在运营商网络上。五、写在最后LESMS 的架构没有炫技,就是一个务实的企业级方案:用 Django 快速搞定业务和管理后台用 Go 保证核心链路的性能和稳定性用 Redis 解耦同步压力和异步处理用 Vue 提供现代化的用户体验这套架构支撑过日发送量百万级的业务,也经历过双 11 的流量洪峰。它不是最完美的,但在开发效率、运维成本、性能表现之间找到了一个不错的平衡点。下篇文章,我会带你 15 分钟把这套环境在本地跑起来,从安装依赖到发出第一条测试短信,手把手教你踩完所有的坑。本文基于 LESMS 开源项目撰写,如需了解更多实现细节,可参考项目文档或源码。
-
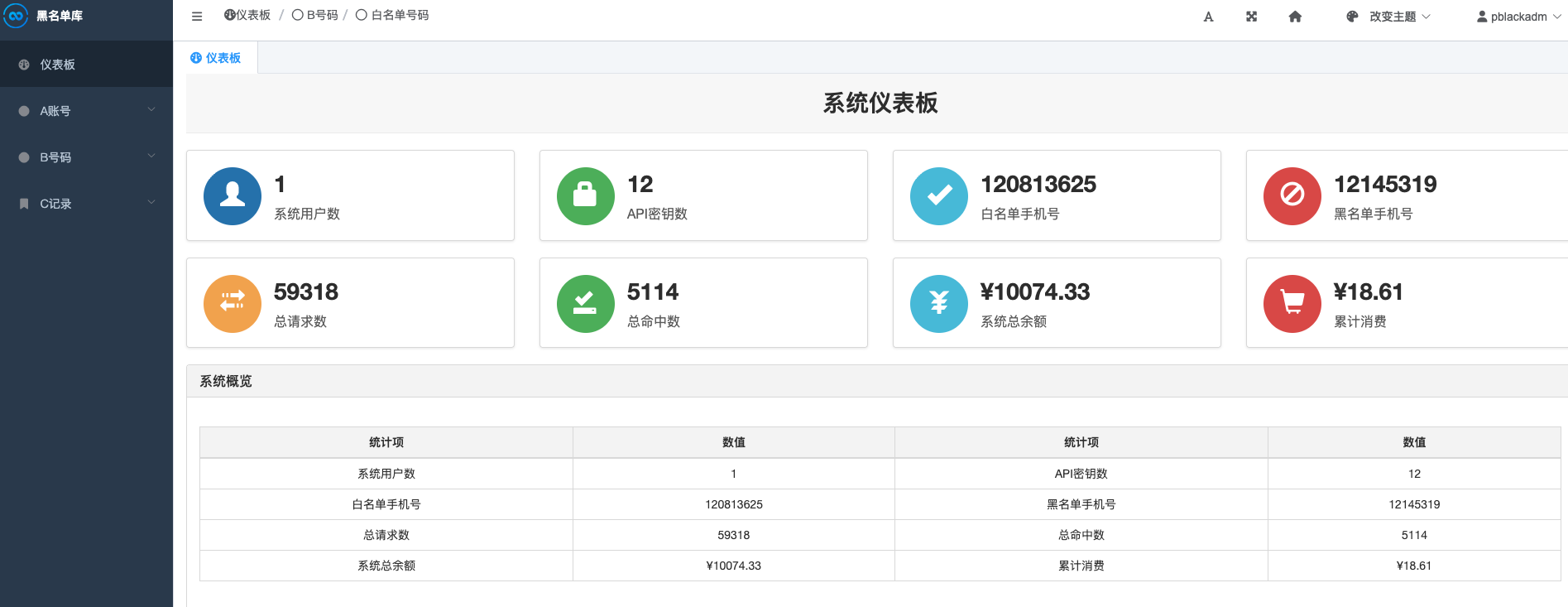
手机号黑名单库查询逻辑与性能优化分享 在高并发场景下,如何实现毫秒级的手机号黑名单校验?本文将深入剖析一个生产级黑名单系统的核心架构与技术实现。一、总体介绍在短信通道、语音呼叫、风控审核等业务场景中,手机号黑名单校验是一项高频且关键的能力。想象一下,当用户发起呼叫或发送短信时,系统需要在毫秒级时间内判断目标号码是否在黑名单中——这直接关系到业务合规性和用户体验。本文介绍的手机号黑名单库是一个面向运营/风控场景的完整解决方案,具备以下核心特性:双通道架构:Django 管理后台 + Go 高性能 API 服务毫秒级响应:依托 Redis 缓存实现单次查询 < 5ms百万级数据支持:轻松支撑千万级黑名单数据量灵活接入方式:支持单号查询、批量查询(最多 500 个)二、技术要点1. Redis Set 数据结构:空间换时间的极致实践是什么:使用 Redis 的 Set(集合)数据结构存储黑名单手机号,而非传统的 Hash 或 String。为什么这么做:Set 的 SISMEMBER 命令时间复杂度为 O(1),无论数据量多大,查询性能恒定内存占用优化:存储 1000 万个 11 位手机号仅需约 400MB 内存天然去重:Set 自动处理重复号码,简化业务逻辑核心价值:单机 Redis 可支撑 10 万+ QPS 的查询压力,满足绝大多数业务场景。2. 冷热分离架构:PostgreSQL + Redis 双层存储是什么:PostgreSQL 作为持久化存储(冷数据),Redis 作为查询缓存(热数据)。为什么这么做:数据安全:PostgreSQL 保证数据不丢失,支持事务和备份查询性能:Redis 避免频繁访问数据库,减轻 DB 压力水平扩展:Redis 可部署集群模式,支持数据分片核心价值:兼顾数据可靠性和查询性能,实现"写入慢、读取快"的最优解。3. 原子切换机制:零停机数据更新是什么:使用临时 Set + RENAME 命令实现黑名单数据的无缝切换。为什么这么做:避免更新过程中的数据不一致问题切换操作是原子性的,微秒级完成业务层无感知,零停机时间核心价值:支持百万级数据的全量更新,而不影响线上查询服务。4. Pipeline 批量查询:网络延迟优化是什么:使用 Redis Pipeline 技术批量发送查询命令,减少网络往返次数。为什么这么做:单次网络 RTT 约 1-5ms,批量查询可将 500 个号码的查询时间从 2500ms 降至 10ms减少 Redis 服务器处理开销核心价值:批量查询接口支持 500 个号码一次性校验,响应时间 < 50ms。5. 签名验证机制:API 安全防护是什么:基于 MD5 的参数签名验证,防止接口被恶意调用。为什么这么做:防止请求被篡改(如修改查询号码)防止重放攻击(时间戳有效期 5 分钟)身份认证(AppId + AppSecret 模式)核心价值:确保只有授权用户才能访问黑名单查询服务。三、核心代码片段1. Redis 批量查询实现// BatchIsPhoneInBlacklistSet 使用 Pipeline 批量查询号码是否在黑名单中 func BatchIsPhoneInBlacklistSet(phones []string) (map[string]bool, error) { if len(phones) == 0 { return make(map[string]bool), nil } pipe := RedisClient.Pipeline() cmds := make(map[string]*redis.BoolCmd) // 批量发送 SISMEMBER 命令 for _, phone := range phones { cmds[phone] = pipe.SIsMember(ctx, BlacklistSetKey, phone) } // 执行所有命令(一次网络往返) _, err := pipe.Exec(ctx) if err != nil { return nil, err } // 处理结果 results := make(map[string]bool) for phone, cmd := range cmds { isMember, err := cmd.Result() if err != nil { // 单个查询出错,默认不在黑名单 results[phone] = false } else { results[phone] = isMember } } return results, nil }核心逻辑解读:使用 Pipeline 将多个 SISMEMBER 命令打包发送所有查询共享一次网络往返,大幅降低延迟结果逐个解析,单个失败不影响整体2. 原子切换实现// AtomicSwitchBlacklist 原子切换黑名单数据 func AtomicSwitchBlacklist() error { // 检查临时 Set 是否存在 exists, err := RedisClient.Exists(ctx, BlacklistTempSetKey).Result() if err != nil { return err } if exists == 0 { return fmt.Errorf("temporary blacklist set does not exist") } // 原子操作:重命名临时 Set 为主 Set pipe := RedisClient.Pipeline() pipe.Rename(ctx, BlacklistTempSetKey, BlacklistSetKey) pipe.Incr(ctx, BlacklistVersionKey) _, err = pipe.Exec(ctx) return err }核心逻辑解读:RENAME 命令是原子操作,微秒级完成版本号递增,便于追踪数据更新状态切换期间查询不中断,业务零感知3. 签名验证实现// GenerateSignature 生成请求签名 func GenerateSignature(params SignParams) string { // 构建参数字典 paramMap := make(map[string]string) paramMap["appId"] = params.AppId paramMap["callee"] = params.Callee paramMap["level"] = strconv.Itoa(params.Level) paramMap["timestamp"] = params.Timestamp // 按字典序排序(确保签名一致性) keys := make([]string, 0, len(paramMap)) for k := range paramMap { keys = append(keys, k) } sort.Strings(keys) // 拼接签名字符串 var signStr strings.Builder for i, key := range keys { if i > 0 { signStr.WriteString("&") } signStr.WriteString(key) signStr.WriteString("=") signStr.WriteString(paramMap[key]) } signStr.WriteString("&appSecret=") signStr.WriteString(params.AppSecret) // MD5 加密 hash := md5.Sum([]byte(signStr.String())) return hex.EncodeToString(hash[:]) }核心逻辑解读:参数按字典序排序,确保客户端和服务端生成相同签名AppSecret 仅参与签名计算,不传输,防止泄露MD5 算法兼顾安全性和计算性能4. 批量查询接口处理// ProcessBatchCheck 处理批量号码检查请求 func (s *BlacklistService) ProcessBatchCheck(req *models.BatchCheckRequest, clientIP string) (*models.BatchCheckResponse, error) { // 1. 验证 API 密钥和签名 params := map[string]interface{}{ "appId": req.AppId, "callee": req.Callee, "level": req.Level, "timestamp": req.Timestamp, } apiKey, err := s.ValidateAndGetApiKey(req.AppId, req.Sign, params) if err != nil { return &models.BatchCheckResponse{ Code: 405, // 签名验证失败 Msg: "签名验证失败", }, nil } // 2. 检查访问权限(IP 白名单等) allowed, err := database.ValidateAccess(apiKey.CUserId, req.AppId, apiKey.ID, clientIP) if !allowed { return &models.BatchCheckResponse{ Code: 403, Msg: "访问被拒绝", }, nil } // 3. 解析并去重电话号码 phones := strings.Split(req.Callee, ",") uniquePhones := make(map[string]bool) var validPhones []string for _, phone := range phones { phone = strings.TrimSpace(phone) if phone != "" && utils.IsValidPhoneNumber(phone) { if !uniquePhones[phone] { uniquePhones[phone] = true validPhones = append(validPhones, phone) } } } // 4. 限制批量查询数量 if len(validPhones) > 500 { return &models.BatchCheckResponse{ Code: 400, Msg: "批量查询数量不能超过500个", }, nil } // 5. 执行批量查询(Level 1=黑名单, 2=白名单, 3=混合模式) results, hitCount, err := s.checkBatchNumbersWithResults(validPhones) // 6. 记录访问日志和消费记录(异步) s.recordAccessAndConsumption(apiKey, validPhones, hitCount) return &models.BatchCheckResponse{ Code: 200, Msg: "success", Data: results, }, nil }核心逻辑解读:六层校验:签名验证 → 权限检查 → 参数解析 → 数量限制 → 黑名单查询 → 日志记录支持三种查询模式:黑名单、白名单、混合模式异步记录访问日志,不阻塞查询响应四、总结手机号黑名单库的核心设计思想可以概括为:"冷热分离保安全,Redis 缓存保性能,原子切换保稳定,签名验证保安全"。通过本文介绍的技术方案,我们实现了:单次查询延迟 < 5ms批量 500 个号码查询 < 50ms支持千万级黑名单数据零停机数据更新这套方案已在生产环境稳定运行,日均处理查询请求数百万次。希望本文的技术分享能为你的黑名单系统设计提供参考。本文基于 PBlack 手机号黑名单管理系统(Django + Go + Redis + PostgreSQL)生产实践整理。
-
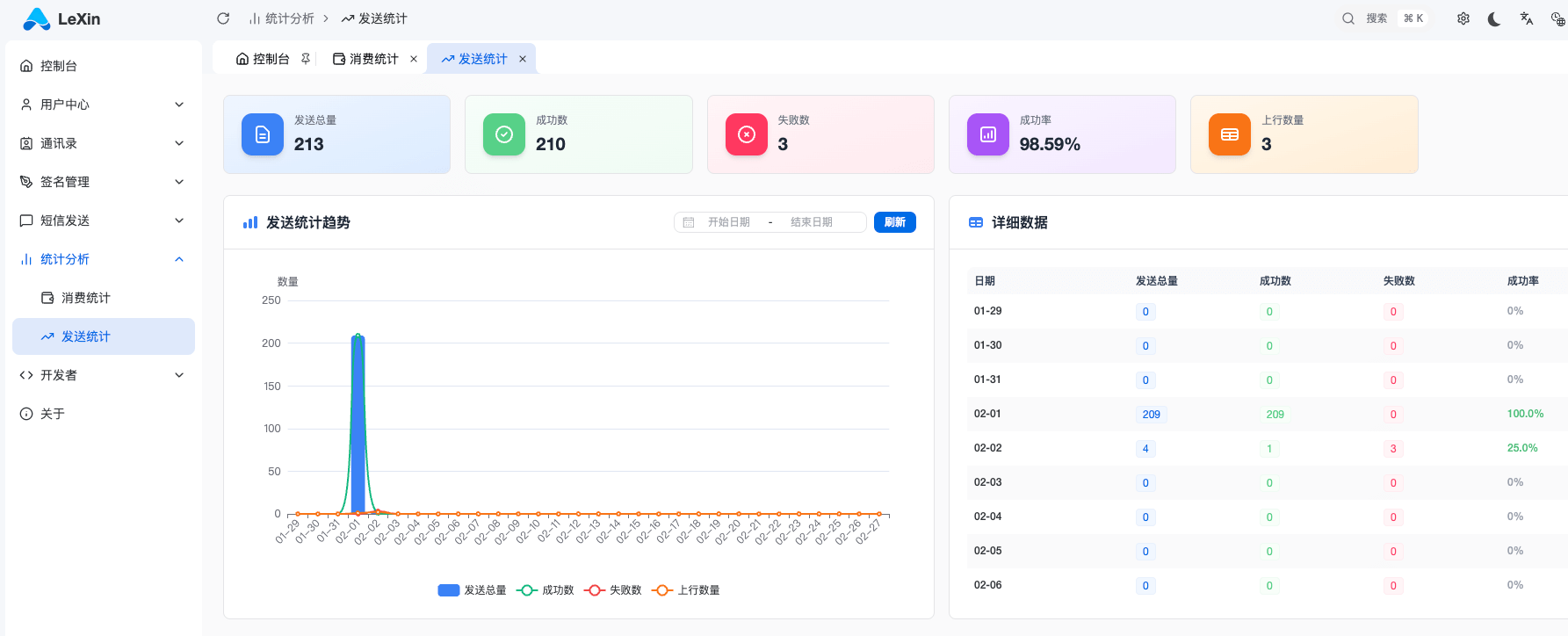
短信通道管理平台之多层架构与Worker异步处理设计分享 今天来聊聊我们在构建企业级短信平台时的一些架构设计心得。短信服务看似简单,但要在高并发场景下保证稳定性、可观测性和可扩展性,背后的技术选型与架构设计才是关键。一、总体介绍1.1 解决的问题在短信业务中,我们面临几个核心挑战:高并发写入:营销活动期间,短时间内可能有数万条短信发送请求涌入实时性与可靠性的平衡:用户希望短信立即发出,但下游通道往往有速率限制多维度统计:需要实时统计发送量、成功率、计费信息风控合规:黑名单过滤、敏感词检测必须在发送前完成1.2 在平台中的位置本文介绍的架构设计是整个短信平台的"中枢神经",位于 API 接入层与下游通道之间,承担着请求调度、异步处理、数据持久化的核心职责。1.3 核心价值通过"分层架构 + Worker 异步处理"的设计,我们实现了:解耦:API 层只负责接收请求,具体处理交给 Worker削峰:利用队列缓冲突发流量可扩展:Worker 可以水平扩容可观测:每个组件都有独立的日志输出二、技术要点2.1 三层架构设计我们的平台采用经典的三层架构:┌─────────────────────────────────────────────────────────────┐ │ 前端 (Vue 3) │ │ customer-web - Vben Admin 框架 │ └───────────────────────────┬─────────────────────────────────┘ │ ┌───────────────────────────▼─────────────────────────────────┐ │ Nginx 反向代理 │ └───────────────┬───────────────────────────┬─────────────────┘ │ │ ┌───────────────▼───────────┐ ┌───────────▼─────────────────┐ │ Django 管理后台 │ │ Go API 服务 │ │ (ladmin) │ │ (lsms-api) │ │ - 用户管理 │ │ - 短信发送 API │ │ - 模板/签名审核 │ │ - 调度器 │ │ - 充值管理 │ │ - Worker 集群 │ │ - 统计报表 │ │ - 计费 Worker │ │ │ │ - 统计 Worker │ │ │ │ - 黑名单 Worker │ └───────────────┬───────────┘ └───────────┬─────────────────┘ │ │ ┌───────────────▼───────────────────────────▼─────────────────┐ │ PostgreSQL + Redis │ │ 数据持久化 + 缓存/队列 │ └─────────────────────────────────────────────────────────────┘技术选型考量:Vue 3 + Vben Admin:现代化前端生态,组件丰富,适合构建复杂的运营后台Django:成熟的企业级后台框架,自带 Admin 界面,适合快速开发管理功能Go API 服务:高并发、低延迟,适合短信发送这类 IO 密集型场景PostgreSQL:ACID 事务、JSONB 支持,适合存储复杂的业务数据Redis:高性能缓存与队列,支撑高并发与解耦2.2 Worker 异步处理机制Worker 是我们架构的核心创新点。当 API 接收到发送请求后,不会立即处理,而是:写入队列:将任务推入 Redis 队列记录日志:在 PostgreSQL 中创建发送记录异步处理:多个 Worker 从队列中拉取任务并行处理flowchart TD Start(["接收发送请求"]) --> Validate["校验签名/限流/鉴权"] Validate --> Enqueue["写入发送队列(Redis)"] Enqueue --> Record["记录发送记录(PostgreSQL)"] Record --> Dispatch["调度器分发任务"] Dispatch --> Billing["计费 Worker 处理"] Dispatch --> Stats["统计 Worker 处理"] Dispatch --> Blacklist["黑名单过滤 Worker 处理"] Billing --> Update["更新计费/余额"] Stats --> UpdateStats["更新统计指标"] Blacklist --> FilterOK{"命中黑名单?"} FilterOK --> |是| Drop["丢弃/标记失败"] FilterOK --> |否| Send["下发到通道"] Send --> Done(["完成"]) Drop --> Done Update --> Done UpdateStats --> DoneWorker 类型说明:Worker 类型职责配置参数调度 Worker扫描定时任务、分发消息dispatcher_count: 2计费 Worker计算费用、扣减余额worker_count: 2, batch_size: 500统计 Worker汇总发送数据、生成报表scan_interval: 60s, batch_size: 1000黑名单 Worker过滤黑名单号码worker_count: 4, cache_ttl: 600s2.3 Nginx 反向代理与负载均衡Nginx 作为入口网关,承担着流量分发、SSL 终止、静态资源缓存等职责:server { listen 443 ssl; server_name sms.hongboxinhua.com; # API requests proxy to ladmin backend location /basic-api/ { proxy_pass http://172.17.0.1:3038/api/v1/customer/; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; # Increase buffer sizes for API responses proxy_buffer_size 128k; proxy_buffers 4 256k; proxy_busy_buffers_size 256k; } # Static files caching location ~* \.(css|js)$ { expires 1y; add_header Cache-Control "public, immutable"; } }关键配置解析:proxy_buffer_size:增大缓冲区,避免大响应被截断expires 1y:静态资源长期缓存,减轻服务器压力X-Forwarded-For:传递真实客户端 IP,便于后端限流统计2.4 限流与安全防护我们在 Django 和 Go API 两层都实现了限流:# Django REST Framework 限流配置 REST_FRAMEWORK = { 'DEFAULT_THROTTLE_RATES': { 'anon': '100/minute', 'user': '1000/minute', 'login': '5/minute', 'register': '3/minute', 'send_code': '1/minute', 'customer_api': '60/minute', 'sms_api': '30/minute', }, }限流策略根据接口类型差异化设置:登录注册类接口严格限流,防止暴力破解;短信发送接口限流较宽松,但仍有上限保护。三、核心代码片段3.1 Go API 服务配置# config.yaml - 服务核心配置 server: host: "0.0.0.0" port: 8080 mode: "debug" database: host: "127.0.0.1" port: 5432 user: "postgres" password: "***" dbname: "lesms" max_open_conns: 100 max_idle_conns: 10 redis: host: "localhost" port: 6379 db: 6 pool_size: 100 min_idle_conns: 10 # Worker 配置 worker: dispatcher_count: 2 queue_timeout: 5 schedule_scan_interval: 10 billing: worker_count: 2 batch_size: 500 scan_interval: 300 stats: batch_size: 1000 scan_interval: 60 blacklist: worker_count: 4 cache_ttl: 600配置说明:max_open_conns: 100:数据库连接池大小,避免连接耗尽batch_size:Worker 批量处理数量,平衡吞吐与延迟cache_ttl: 600:黑名单缓存 10 分钟,减少数据库查询3.2 日志轮转配置log: level: "debug" dir: "logs" max_size: 100 # 单个日志文件最大 100MB max_backups: 30 # 保留 30 个历史文件 max_age: 7 # 保留 7 天 compress: true # 压缩旧日志每个组件都有独立的日志文件:lsms-api.log - API 服务日志dispatcher.log - 调度 Worker 日志billing.log - 计费 Worker 日志stats.log - 统计 Worker 日志blacklist.log - 黑名单 Worker 日志【放一张日志目录结构截图】3.3 数据库连接池配置# Django 数据库配置 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'lesms', 'USER': 'postgres', 'PASSWORD': '***', 'HOST': '127.0.0.1', 'PORT': '5432', } }四、实际效果通过这套架构,我们在生产环境实现了:峰值处理能力:单机可处理 5000+ TPS 的发送请求平均延迟:从请求接收到入队 < 50ms系统可用性:99.9%(过去 6 个月数据)故障隔离:单个 Worker 故障不影响整体服务五、总结与展望本文介绍了短信通道管理平台的核心架构设计,重点包括:三层架构:前端 + Django 后台 + Go API 服务,职责清晰Worker 异步处理:解耦、削峰、可扩展完善的可观测性:多维度日志、监控大盘安全防护:多层限流、黑名单过滤后续文章我们将深入探讨:短信通道的智能路由与故障转移黑名单系统的设计与优化高并发场景下的数据库优化实践
-
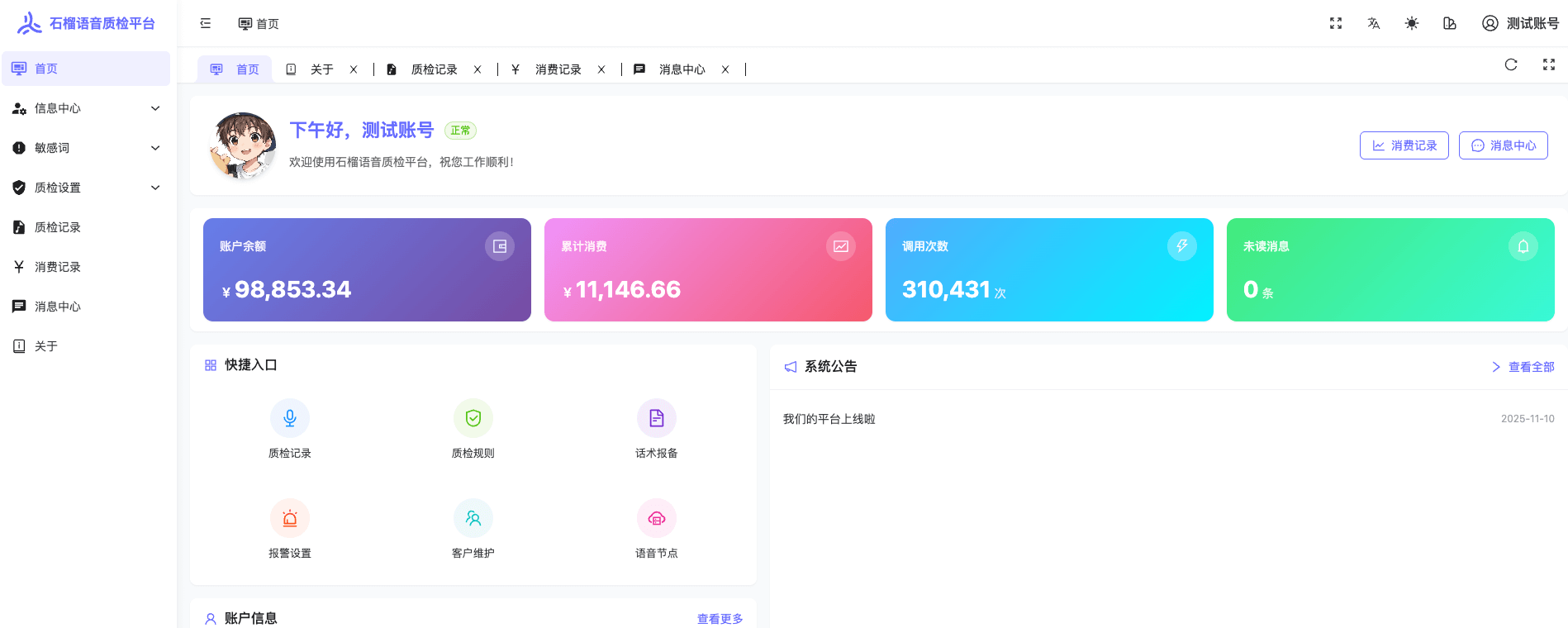
CVOICE语音质检系统:一个看板掌控全局,管理看板深度解析 总体介绍在语音质检系统中,运营管理者面临的最大痛点之一就是信息分散:用户数据、录音状态、敏感词告警、财务消费……分布在不同页面,想要全面了解系统运行状况,需要反复切换、手动汇总。CVOICE语音质检系统的管理看板(Dashboard)正是为解决这一问题而生。它将系统中最核心的运营指标——用户数量、节点状态、录音处理进度、告警消息、财务概览、质检规则排行——全部汇聚在一个页面上,配合可视化图表和实时统计,让管理者打开浏览器就能"一眼看穿"系统全貌。无论是日常巡检还是异常排查,看板都能成为你的"数字驾驶舱"。技术要点1. 后端架构:自定义 Django AdminSiteCVOICE的管理看板并非使用第三方BI工具,而是基于Django Admin框架进行了深度定制。通过继承 AdminSite 类,注册自定义URL,将看板页面无缝嵌入到后台管理系统中:class CustomAdminSite(AdminSite): site_header = '语音质检平台' def get_urls(self): urls = super().get_urls() custom_urls = [ path('dashboard/', self.admin_view(self.dashboard_view), name='dashboard'), path('realtime-stats/', self.admin_view(self.realtime_stats_view), name='realtime_stats'), ] return custom_urls + urls这种方式的好处是:看板天然继承了Django Admin的认证和权限体系,只有经过身份验证的管理员才能访问,无需额外实现鉴权逻辑。2. 多维度数据聚合看板页面在一次请求中完成了超过30项指标的实时计算,覆盖6大维度:维度核心指标数据来源用户管理总用户数、活跃/禁用/欠费分布CUser模型节点状态在线/离线、审核状态分布CUserAgent模型录音处理总量、今日新增、检测状态分布PhoneRecording模型语音转写转写总量、审核状态、质检结果SpeechToText模型告警消息总量、待处理数AlertMessage模型财务统计总余额、累计消费、今日消费ConsumptionRecord模型所有查询均使用Django ORM的 count()、aggregate(Sum()) 和 filter() 链式调用,保持了代码的简洁性和可维护性。3. 可视化图表:Chart.js驱动看板中集成了两类动态图表,均由 Chart.js 4.x 渲染:近7天录音趋势折线图:展示系统整体的录音采集量走势,帮助发现异常波动。节点维度录音趋势:取录音量TOP5的节点,按天展示各自的录音增长曲线,便于定位"高产"或"沉默"节点。图表数据在后端通过循环计算7天内每天的录音数量,序列化为JSON后传递给前端模板:for i in range(6, -1, -1): day = today - timedelta(days=i) day_start = timezone.make_aware(timezone.datetime.combine(day, timezone.datetime.min.time())) day_end = day_start + timedelta(days=1) count = PhoneRecording.objects.filter( created_at__gte=day_start, created_at__lt=day_end ).count() daily_recordings.append(count)4. 质检规则排行榜看板底部设计了质检规则排行榜,从两个角度排名:按录音条数排序:哪条规则命中的录音最多?按总音频时长排序:哪条规则覆盖的通话总时长最长?这为规则优化和资源分配提供了直观的数据支撑。核心代码/配置片段看板的前端采用 Bootstrap 5 构建响应式布局,使用CSS渐变变量统一视觉风格::root { --primary-gradient: linear-gradient(135deg, #667eea 0%, #764ba2 100%); --success-gradient: linear-gradient(135deg, #11998e 0%, #38ef7d 100%); --warning-gradient: linear-gradient(135deg, #f093fb 0%, #f5576c 100%); }每个指标卡片通过统一的 stat-card 组件展示,支持趋势标识(如"今日+N"):<div class="stat-card info"> <div class="d-flex align-items-center"> <div class="stat-icon info"><i class="bi bi-mic-fill"></i></div> <div class="ms-3"> <div class="stat-value">{{ total_recordings }}</div> <div class="stat-label">电话录音</div> </div> </div> <div class="stat-trend up"> <i class="bi bi-plus-circle"></i> 今日 +{{ today_recordings }} </div> </div>生产环境使用 Gunicorn 作为WSGI服务器,配合 systemd 实现进程管理和自动重启:ExecStart=/opt/miniconda3/envs/cvoice/bin/gunicorn \ --workers 2 \ --bind 0.0.0.0:3008 \ --worker-class sync \ --max-requests 1000 \ cvoice.wsgi:application总结CVOICE管理看板通过Django Admin深度定制 + Chart.js可视化 + Bootstrap响应式布局,在一个页面内实现了30+核心指标的实时聚合展示。它不仅是运维人员的"第一屏",更是整个语音质检系统运行状态的晴雨表。下一篇,我们将深入探讨看板中"实时数据统计"页面的48小时逐时分析功能——它如何按节点、按规则维度呈现细粒度的录音分布,帮你精准把控每一个时段的系统脉搏。敬请期待!
-
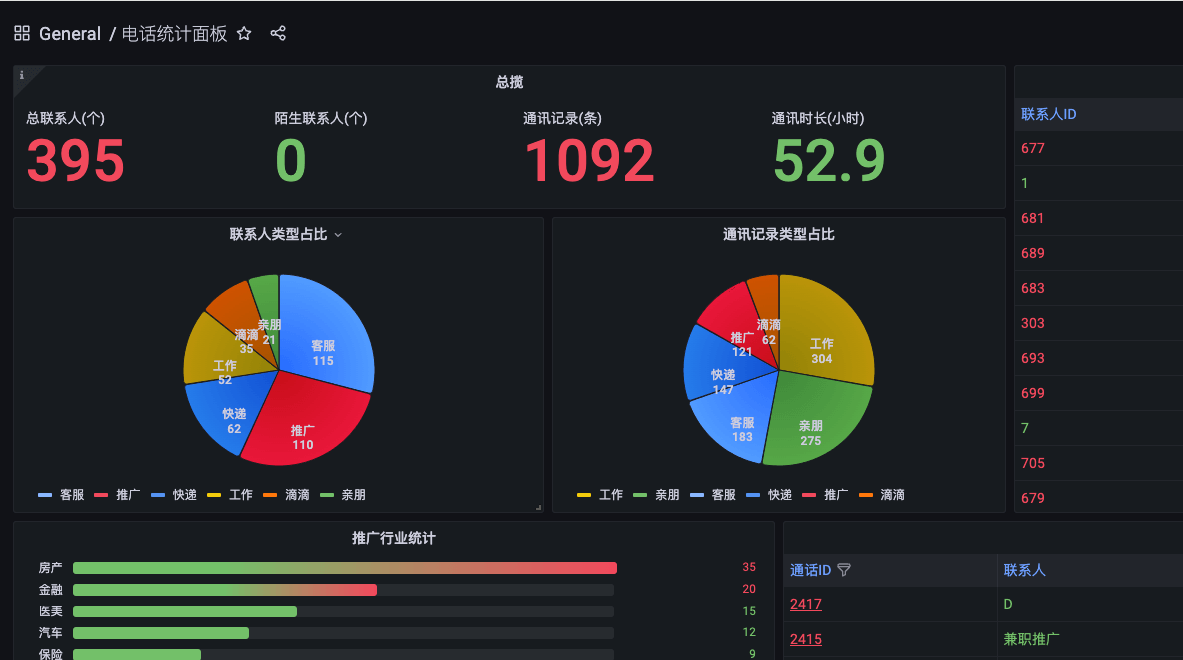
基于Django的录音管理系统的开发总结 前言安卓手机默认打开了通话录音功能,几年下来积攒了上千条录音,一直懒得清理。最近写了一个管理系统,将所有录音文件导入。进行可视化分析,给自己几年打的所有电话生成一份报告。更直观的展示自己的通讯情况。{card-default label="统计" width="80%"}{/card-default}开发过程录音文件的管理通过django框架开发,主要功能点有通讯录管理、录音文件管理、录音文件转文字管理。转文字通过调用腾讯api完成,将结果保存到数据库,便于查询。可视化模块通过grafana直接读取mysql数据实现。模型类的设计模型类包括三种,Contact类、CallRecord类和RecordResult类。Contact类存储通讯录信息,包含名称和号码等class Contact(models.Model): number = models.CharField(max_length=15,verbose_name='电话号码') # 电话号码 name = models.CharField(blank=True,null=True,max_length=100,verbose_name='联系人') # 联系人姓名 # 新增的类型字段 TYPE_CHOICES = [ ('family', '亲朋'), ('work', '工作'), ('promotion', '推广'), ('taxi', '滴滴'), ('service', '客服'), ('delivery', '快递'), ] contact_type = models.CharField( max_length=10, choices=TYPE_CHOICES, verbose_name='类型', default='promotion', # 默认值为'亲朋' ) def __str__(self): return self.number class Meta: verbose_name = '通讯录' verbose_name_plural = '通讯录'CallRecord类用于存储音频文件、状态、音频转文字的任务信息等class CallRecord(models.Model): phone_number = models.ForeignKey(Contact, related_name='call_records', on_delete=models.CASCADE) # 电话号码外键 call_time = models.DateTimeField(verbose_name='时间') # 通话时间 recording_file = models.CharField(max_length=255, blank=True, null=True, verbose_name='文件名') # 录音文件名 notes = models.TextField(blank=True, null=True, verbose_name='备注') # 备注 task_id = models.CharField(max_length=255, blank=True, null=True, verbose_name='任务id') # 任务ID,可为空 # 状态字段的选择 STATUS_CHOICES = [ ('未处理', '未处理'), # Unprocessed ('处理中', '处理中'), # Processing ('已完成', '已完成'), # Completed ] status = models.CharField(max_length=10, choices=STATUS_CHOICES, default='未处理', verbose_name='状态') # 状态,默认值为 '未处理' def __str__(self): return f"{self.phone_number.number} - {self.call_time}" # 返回通话记录的字符串表示 class Meta: verbose_name = '通话录音' # 该模型的单数名称 verbose_name_plural = '通话录音' # 该模型的复数名称RecordResult用于管理存储音频转文字的结果等信息class RecordResult(models.Model): call_record = models.OneToOneField(CallRecord, related_name='record_result', on_delete=models.CASCADE) # 与 CallRecord 的一对一关系 # 录音时长,单位为秒 duration = models.PositiveIntegerField(verbose_name='时长') # 时长,正整数 # 错误信息,可以为空 error_message = models.TextField(blank=True, null=True, verbose_name='错误') # 错误信息,可为空值 # 文本结果,可以为空 text_result = models.TextField(blank=True, null=True, verbose_name='全文') # 文本结果,可为空 # 文本大纲,可以为空 text_outline = models.TextField(blank=True, null=True, verbose_name='大纲') # 文本大纲,可为空 # 标签,可以为空 tags = models.CharField(max_length=255, blank=True, null=True, verbose_name='标签') # 标签,最多 255 字符,可以为空 # 备注,可以为空 notes = models.TextField(blank=True, null=True, verbose_name='备注') # 备注,可为空 def __str__(self): return f"{self.call_record.phone_number.number} - {self.duration}" class Meta: verbose_name = '通话文本' # 模型的单数名称 verbose_name_plural = '通话文本' # 模型的复数名称接口设计录音文件入库、文本结果处理等任务过程中用到的各种接口。# 防止重复入库的接口 class CheckRecordingFile(APIView): def post(self, request): # 获取file_name参数 file_name = request.data.get('file_name') if not file_name: return Response({"error": "file_name is required"}, status=status.HTTP_400_BAD_REQUEST) # 查询CallRecord中是否有这个file_name record_exists = CallRecord.objects.filter(recording_file=file_name).exists() # 根据查询结果返回True或False if record_exists: return Response({"exists": True}, status=status.HTTP_200_OK) else: return Response({"exists": False}, status=status.HTTP_200_OK) #录音在线播放用到的接口 class AudioList(APIView): def get(self, request): mediaList = [] # 获取URL查询字符串中的rid参数 rid = request.query_params.get('rid') cid = request.query_params.get('cid') if rid: mediaList = CallRecord.objects.filter(id=rid) if cid: contact = Contact.objects.get(id=cid) mediaList = CallRecord.objects.filter(phone_number=contact) arr = [] #倒序 for item in mediaList[::-1]: # 随机1-10专辑封面图片 sui_num = random.randint(1, 10) #构建 arr.append({ 'id': item.id, 'title': f"{item.record_result.id} - {item.phone_number.number} - {item.call_time}", 'singer': f"{item.phone_number.name}", 'songUrl': f"{settings.MEDIA_URL}{urllib.parse.quote(item.recording_file)}", 'imageUrl': '/static/images/' + str(sui_num) + '.png', }) return Response({'list': arr}, status=status.HTTP_201_CREATED)录音文件同步手机中的通讯录音会自动传输到家庭nfs,管理系统会单独启动一个循环任务去nfs拉取音频文件入库并创建音频转文字任务。import subprocess import time from datetime import datetime # 定义需要执行的命令 commands = [ "mkdir -p /tmp/lxnfs", "mount -t smbfs //189xxxxx805:zhixxxx6@192.168.1.150/7460088 /tmp/lxnfs", "cp -n /tmp/lxnfs/来自ADT-AN00的手机备份/文件夹备份/* /Users/xinei/project/audioman/data/files/ || true", "umount /tmp/lxnfs" ] # 定义一个函数来执行这些命令 def run_commands(): for command in commands: try: # 执行每条命令 subprocess.run(command, shell=True, check=True) print(f"执行成功: {command}") except subprocess.CalledProcessError as e: print(f"命令执行失败: {command}\n错误信息: {e}") # 主循环,每小时检查一次时间 while True: current_time = datetime.now() # 只在 20:00 到 24:00 之间执行命令 if current_time.hour >= 20 and current_time.hour < 23: print(f"当前时间: {current_time}. 在允许的时间范围内,执行命令。") run_commands() else: print(f"当前时间: {current_time}. 不在允许的时间范围内,跳过执行。") # 等待 1 小时再检查时间 time.sleep(3600)录音文件转文字录音文件写入数据库后,默认状态为待处理。另一个脚本会自动扫描未处理的记录,然后自动创建处理任务。# 监控指定目录 def monitor_directory(path): observer = None event_handler = MyEventHandler() try: while True: current_time = datetime.now() # 只在20:00到24:00之间执行监控 if current_time.hour >= 20 and current_time.hour < 24: if observer is None: # 只有在 observer 没有启动时才创建新的观察者 observer = Observer() observer.schedule(event_handler, path, recursive=False) observer.start() print(f"当前时间: {current_time}. 启动监控。") else: if observer is not None: observer.stop() observer.join() # 等待线程停止 observer = None # 将 observer 置为 None,以便后续创建新的实例 print(f"当前时间: {current_time}. 停止监控。") time.sleep(3600) # 每小时检查一次时间 time.sleep(600) # 每次监控状态保持10分钟,然后再循环检查 except KeyboardInterrupt: if observer is not None: observer.stop() observer.join() if __name__ == "__main__": directory_to_watch = "/files/" # 替换为你要监控的目录 monitor_directory(directory_to_watch)可视化过程可视化通过grafana实现。直接链接mysql数据库,通过sql查询数据并返回,具体页面如开头所示。完整项目代码获取【统计分析】基于Django开发的录音管理系统源码
-
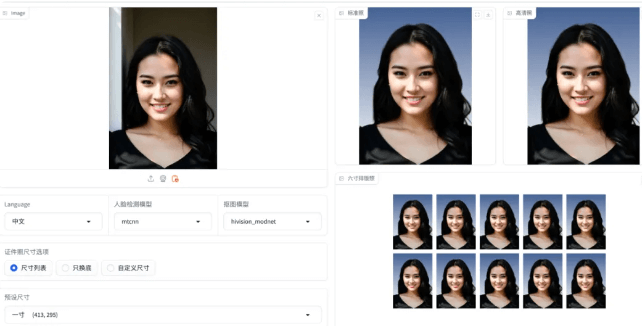
爆火的轻量级AI证件照工具HivisionIDPhotos部署过程 前言HivisionIDPhotos是一款轻量级的AI证件照制作工具,它利用先进的图像处理技术和机器学习算法,简化了证件照的制作流程,确保生成的照片既符合官方证件的尺寸要求,又保持了高质量。无论是申请护照、驾照还是学生证,我们都可以用它来快速生成符合标准的证件照。{card-default label="制作界面" width="90%"}{/card-default}项目地址: HivisionIDPhotos部署采用docker启动,docker的安装参考以前的教程。部署很简单直接docker启动即可。基本环境docker和docker-compose一键安装脚本项目启动docker-compose up 项目文件:version: '3.8' services: hivision_idphotos: build: context: . dockerfile: Dockerfile image: linzeyi/hivision_idphotos command: python3 -u app.py --host 0.0.0.0 --port 7860 ports: - '3000:7860' hivision_idphotos_api: build: context: . dockerfile: Dockerfile image: linzeyi/hivision_idphotos command: python3 deploy_api.py ports: - '8080:8080'测试访问:http://ip:7860上传一张普通照片,然后即可制作。使用简单,制作质量也可以满足要求。{card-default label="制作效果" width="90%"}{/card-default}
-
支付网关DaxPay部署测试改造过程 前言DaxPay单商户是一套开源支付网关系统,已经对接支付宝、微信支付相关的接口。可以独立部署,提供接口供业务系统进行调用,不对原有系统产生影响, 适用于小型项目或简单收单的场景。本文记录部署测试记录。{card-default label="收款页面" width="90%"}{/card-default}核心技术栈JDK,1.8+,11版本可以正常使用,但17+版本暂不支持SpingBoot, 2.7xRedis, 5.x版本以上Mysql,5.7.X以上Vue,前端框架3.x项目部署过程数据库mysql,redis的部署过程略过。可以查阅一下往期的文章。本文主要记录项目代码部署的相关过程。所有项目代码的地址: 【支付源码】开源免费支付系统DaxPay源码数据库创建一个daxpay的数据实例。同时在后端项目中_config/sql目录下找到dax-pay.sql数据库脚本文件,导入daxpay数据库。# 建库 mysql -uroot -pmariadb@xxx -h 127.0.0.1 CREATE DATABASE `daxpay` DEFAULT CHARACTER SET utf8 COLLATE utf8_bin; create user 'dpuser'@'%' IDENTIFIED BY 'dpuserxxx'; grant all privileges on daxpay.* to 'dpuser'@'%'; flush privileges; # 导入demo数据 mysql -udpuser -pdpuserxxx -h 127.0.0.1 daxpay < ./_config/mysql/dax-pay.sqljava环境利用java和maven打包后端代码,在打包之前修改application.yml内的数据库连接信息。# java和maven的安装 yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel wget https://downloads.apache.org/maven/maven-3/3.8.8/binaries/apache-maven-3.8.8-bin.tar.gz tar xvf apache-maven-3.8.8-bin.tar.gz mv apache-maven-3.8.8 /usr/local/maven # maven配置国内源 vim ~/.m2/settings.xml 内容见下面... # maven版本验证 java -version mvn -version # 项目打包 mvn -B clean package -Dmaven.test.skip=true -Dmaven.javadoc.skip=true -Dautoconfig.skipmaven国内源:<settings> <mirrors> <!-- 阿里云镜像 --> <mirror> <id>aliyun</id> <mirrorOf>*</mirrorOf> <url>https://maven.aliyun.com/repository/public</url> </mirror> <!-- 华为云镜像 --> <mirror> <id>hwcloud</id> <mirrorOf>*</mirrorOf> <url>https://mirrors.huaweicloud.com/repository/maven/</url> </mirror> <!-- 清华大学镜像 --> <mirror> <id>tsinghua</id> <mirrorOf>*</mirrorOf> <url>https://mirrors.tuna.tsinghua.edu.cn/maven/</url> </mirror> <!-- 中科大镜像 --> <mirror> <id>ustc</id> <mirrorOf>*</mirrorOf> <url>https://mirrors.ustc.edu.cn/maven/</url> </mirror> </mirrors> </settings>项目启动项目代码在docker内运行,使用docker-compose.yml管理。docker和docker-compose的安装见往期文章。构建docker镜像:隐藏内容,请前往内页查看详情构建命令:docker build -t dax-start:latest .docker-compose.yml内容隐藏内容,请前往内页查看详情前端代码因为项目采用前后端分离架构,前端代码需要单独构建。构建后将代码传输到服务器,然后用nginx服务器提供服务。# 安装node和pnpm环境,博主是mac系统: brew install node@16 pnpm@8 # 配置环境变量 echo 'export PATH="/opt/homebrew/opt/node@20/bin:$PATH"' >> ~/.zshrc echo 'export PATH="/opt/homebrew/opt/pnpm@8/bin:$PATH"' >> ~/.zshrc # 配置国内源 pnpm config set registry https://registry.npmmirror.com # 项目构建 pnpm install pnpm buildnginx服务服务有nginx代理静态资源,前端放caddy用于自动申请ssl证书。nginx配置:隐藏内容,请前往内页查看详情caddy2代理配置:隐藏内容,请前往内页查看详情至此所有配置完成。可以通过web登录后台,配置账号,支付通道等。{card-default label="管理后台" width="80%"}{/card-default}
-
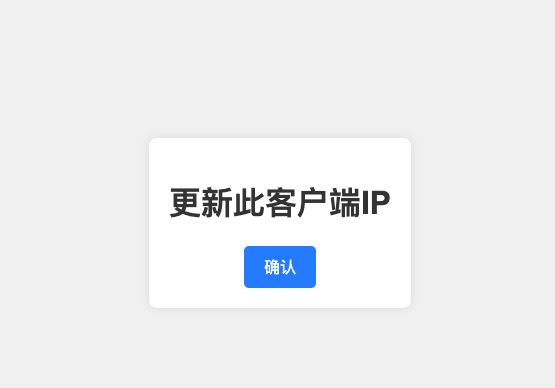
新客户端IP一键过白功能开发与配置 前言部署了一个自己使用的web服务,不想对公网开放。最初用iptables对自己当前的电脑IP开放,禁止其他IP访问。每次路由器重启,或者在外出差,IP经常变动。需要登录服务器,新增新的IP。决定改变控制方式,利用nginx的IP白名单功能,同时用flask写了一个对公网开放的页面。当地址变动时,访问此页面。点击一键更新,就把最新的ip加入到nginx的白名单。同时重新加载nginx配置生效。{card-default label="ip更新页面" width="85%"}{/card-default}被控制服务需要进行ip访问控制,不对公网开放的nginx配置信息。default.conf配置用加载了ip白名单文件whitelist.conf# Appadmin server { listen 80; server_name 0.0.0.0; root /www/web/maccms_v10/; server_tokens off; #include none.conf; index index.php index.html index.htm; access_log /www/web_logs/wp_access.log wwwlogs; error_log /www/web_logs/wp_error.log notice; #auth_basic "请输入用户和密码"; # 验证时的提示信息 #auth_basic_user_file /etc/nginx/password; # 认证文件 location /{ include whitelist.conf; #默认位置路径为/etc/nginx/ 下, #如直接写include whitelist.conf,则只需要在/etc/nginx目录下创建whitelist.conf deny all; } location ~ \.php$ { fastcgi_pass php:9000; fastcgi_index index.php; include fcgi.conf; } #需要注意伪静态的配置 if (!-e $request_filename) { rewrite ^/index.php(.*)$ /index.php?s=$1 last; rewrite ^/api.php(.*)$ /api.php?s=$1 last; rewrite ^/adm0.php(.*)$ /adm0.php?s=$1 last; rewrite ^(.*)$ /index.php?s=$1 last; break; } location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ { expires 30d; } location ~ .*\.(js|css)?$ { expires 12h; } }whitelist.conf文件内存放需要开放的IP,文件内容:allow 101.31.158.153;控制服务文章开头的一键放通页面用flask框架实现, 单独部署app.py主要实现逻辑,有两个接口。一个接口提供页面,一个接口负责获取IP后更新,同时重新加载被控制服务的nginx配置隐藏内容,请前往内页查看详情index.html提供文章开头的一键更新功能的页面代码<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>IP 过白</title> <link rel="stylesheet" href="styles.css"> <!-- Link to external CSS file --> <script src="https://code.jquery.com/jquery-3.6.0.min.js"></script> <style> body { font-family: Arial, sans-serif; display: flex; justify-content: center; align-items: center; height: 100vh; background-color: #f0f0f0; margin: 0; } .container { text-align: center; background-color: #fff; padding: 20px; border-radius: 8px; box-shadow: 0 0 10px rgba(0, 0, 0, 0.1); } h1 { color: #333; } #uploadBtn { background-color: #007bff; color: #fff; border: none; padding: 10px 20px; border-radius: 5px; cursor: pointer; font-size: 16px; transition: background-color 0.3s ease; } #uploadBtn:hover { background-color: #0056b3; } #uploadBtn:focus { outline: none; } </style> </head> <body> <div class="container"> <h1>更新此客户端IP</h1> <button id="uploadBtn">确认</button> </div> <script> $(document).ready(function() { $('#uploadBtn').click(function() { $.ajax({ type: 'POST', url: '/upload_ip', success: function(response) { if (response.status === 'success') { alert('IP 更新成功: ' + response.ip); ('Error: ' + response.message); } }, error: function() { alert('发生错误.'); } }); }); }); </script> </body> </html>服务启动控制服务通过systemd加载,配置文件为:/etc/systemd/system/ipallow.service。配置内容为[Unit] Description=IpAllow App [Service] User=root WorkingDirectory=/opt/ipallow ExecStart=/usr/local/bin/gunicorn -w 2 -b 0.0.0.0:801 app:app Restart=always [Install] WantedBy=multi-user.targetcaddy代理控制服务启动了服务器的801端口,通道caddy2代理到443,然后通过公网可访问。不用nginx代理的原因是控制服务会重启nginx,导致前端页面在等待返回结构时异常。b.test.xyz:443 { tls service@test.xyz encode gzip log { output file /logs/access.log } header / { Strict-Transport-Security "max-age=31536000;includeSubdomains;preload" } #访问认证 basicauth / { cms $2a$14$bNLxxxxxxxxxxxxxxxxxxxxxxGAbzyOUyoBn1rjfpN/O } ## HTTP 代理配置 reverse_proxy http://192.168.0.203:801 { header_up X-Real-IP {http.request.remote.host} header_up X-Forwarded-For {http.request.remote.host} header_up X-Forwarded-Port {http.request.port} header_up X-Forwarded-Proto {http.request.scheme} } }caddy认证密码生产caddy的认证密码caddy hash-password --plaintext 'cmsxxxx'
-